- C++, Python
Key words
- deep neural networks
- tensor operation
- compiler optimization
- loop tiling
- neural processing units
MindSpore and the Auto Kernel Generator
This project is part of a larger effort in the development of MindSpore, an all-scenario deep learning computing framework that can be executed on different hardware, with different architectures, like CPUs, GPUs, and in particular neural processing units, the NPUs. One of the biggest challenges of such a general purpose software is getting the maximum performance that any of these modern hardware architectures can offer.
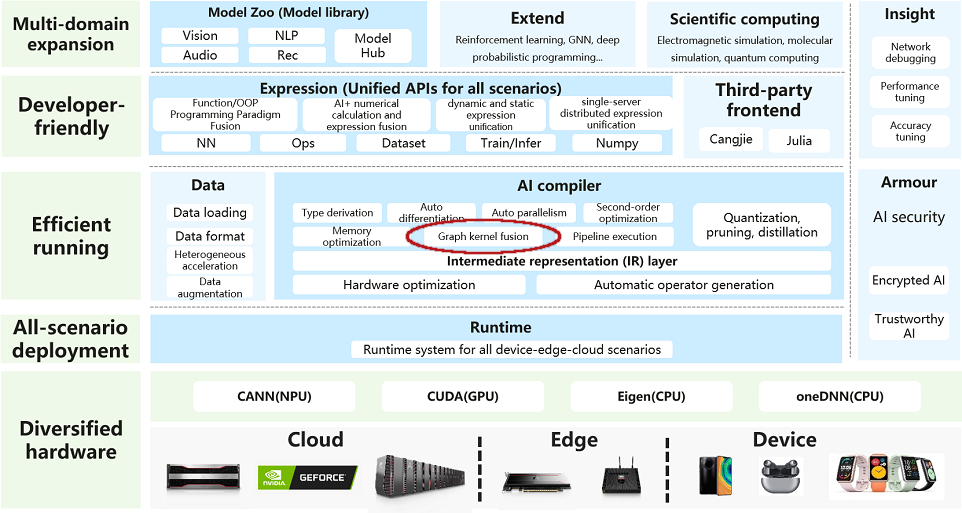
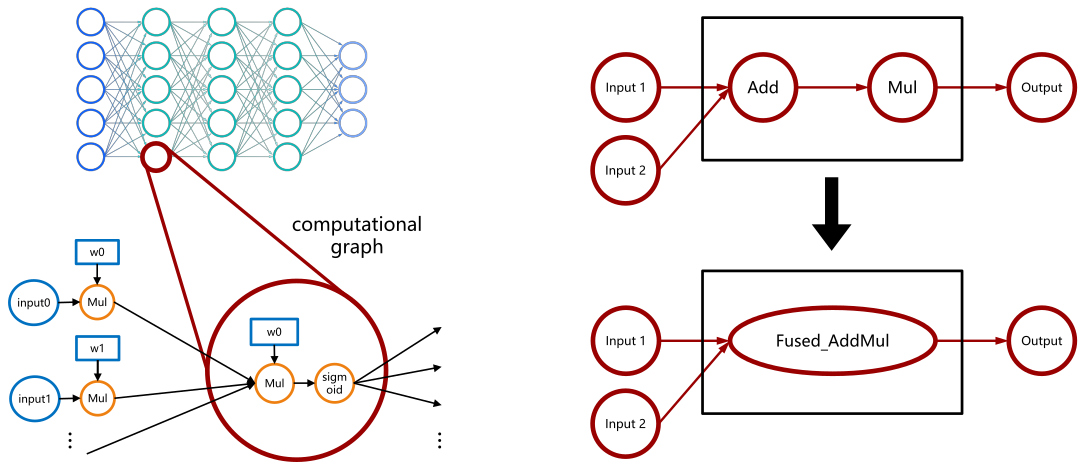
To achieve this goal, a central part is the AI compiler, which must to be able to apply optimizations suitable for the hardware used and appropriate to any deep learning neural network architecture on which it is applied. In particular, important optimizations are provided by the Graph Kernel Fusion, which analyzes/evaluates the compute graph to apply optimizations to operators. First, the deep neural network is expressed as directed acyclic graphs of tensors operations. Graph Kernel Fusion then analyzes and evaluates the computational graph and applies appropriate optimizations to it. For example, it might look at a subgraph from the computing graph and, after analysis, decide that it is optimal to fuse these two operators, the addition of two input tensors followed by a scalar multiplication.
This kind of optimization is done with the help of AKG (Auto Kernel Generator) which generates optimized code from the graph kernel based on the polyhedral method. Within the polyhedral analysis there are several transformations that can be applied, and in particular there is loop tiling.
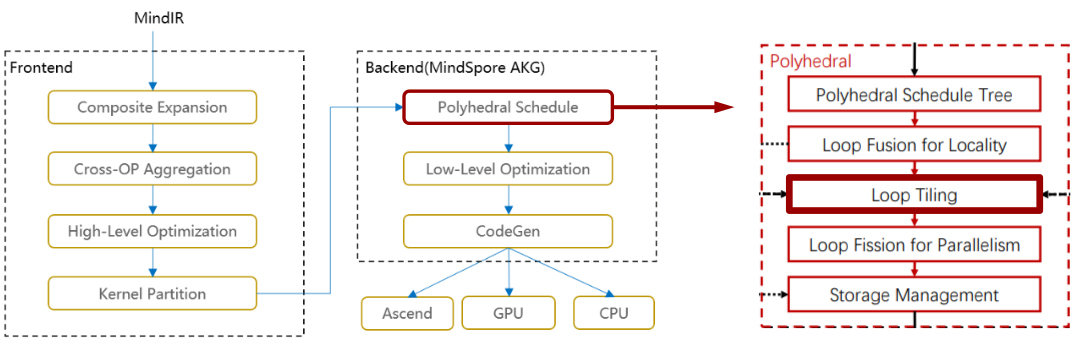
Loop Tiling Optimization
The loop tiling transformation is one of the most important optimizations for computationally intensive tasks. It is a well-known transformation that has been extensively studied since at least the 1980s. This optimization aims to exploit spatial and temporal locality of data accesses, but the reasoning for finding the optimal partition that leads to the best performance depends on many variables. It must take into account the hardware memory hierarchy, their sizes and granularity for computation and communication. The data type and shape, data locality and reuse (that is, which data is already loaded and which of then can be reused or overwritten), and also the hardware can impose alignment constrains. The hardware can also provide parallelization features and so on.
The state-of-the-art solutions for the tiling problem are based on searching for optimization choices. Today’s most popular solution is perhaps the Ansor, which explore combinations of optimizations by sampling programs from a search space represented in a hierarchical way. But depending on the hardware architecture used, the search space can be very complex and may lead to a combinatorial explosion of choices and, therefore, it can be time-consuming. Moreover, this costly searching procedure is usually not transferable, i.e. changes on the deep neural network configuration often require re-tuning.
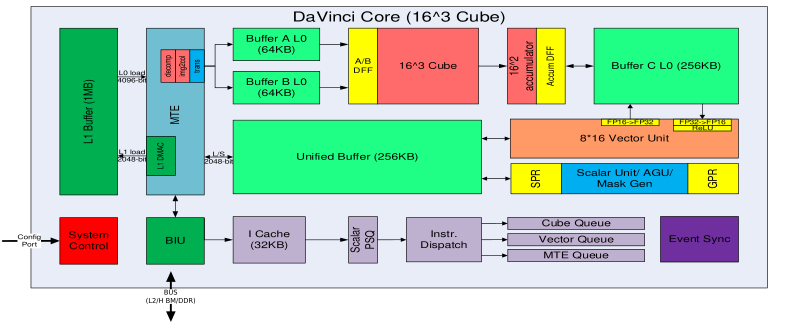
It becomes particularly complicated when the model is to run on modern NPUs, which are accelerators developed for AI specific tasks. Huawei has a family of specialized hardware for hard AI computing, the Atlas products, whose core processors are the Ascend devices, which we have been running and testing our implementation. The Ascend devices contain an AI computing engine, which consists of an AI CPU and an AI core, the latter being built on a very specialized architecture called DaVinci. DaVinci core has three different computing units for cube, vector and scalar with independent execution pipelines, it has different internal storage devices visible to programmers (Unified buffer, L0 and L1 buffer, scalar buffer and registers), and many control units for system control and independent queuing for both data movement and communication.
In this scenario we propose a solution to the tiling problem where through computing graph analysis, combined with compilation and hardware information, the objective is to find a good tile quickly during compilation time - our algorithm execution time is typically 6 orders of magnitude faster than the tuning time of search-based methods. Usually, in a classical tiling solver, the data flow in the computing graph is analyzed without taking into account the high-level information. In our case we also analyzed the intermediate representation (IR), retrieving all the operators and their tensor relationships, but we propose to include compiler/scheduler information (to make it more flexible and allow working with different compilers). We also take into account information from low-level passes to code generation that actually happens afterwards, but that may require extra memory usage for their optimization. Furthermore, we do not follow the exact hardware, but rather do an abstraction where we represent, for example, the Ascend NPU hierarchically, as a tree.
Our solution is enabled by default since AKG r1.9.
Key contributions
- Headed the full refactoring of the new tiling module (modularization, better integration and clean code techniques)
- Implemented the intermediate representation IR parsing
- Implemented the scheduler information extraction
- Several performance improvements
- Implemented test automation for exhaustive testing
- Benchmark evaluation on single fused operators
- Benchmark on end-to-end deep neural networks model training, such as:
- Transformer
- GPT-3
- Bert
- Wide and Deep
- DeepFM
- ResNet50
- YOLO-v3 Darknet-53
- MindSponge Protein Relaxation