- C
Key words
- satisfiability-problem
- conjunctive-normal-form
- k-sat
- k-cnf
- generalized-cover-problem
- dancing-links
- np-complete
Introduction
Given a set U = {x1, x2, … , xn} of boolean variables (literals) and a boolean formula k-CNF (conjunctive normal form composed by “and” of clauses in {c1, c2, …, cm}, where each clause consists in “or” of k literals belonging to the set U plus respective negations), the main objective of this program consists on searching attributions (true and false) for the set of literals such that the k-CNF is satisfied (true). This is a NP-complete problem known as k-SAT.
The k-SAT problem can be interpreted as a generalized cover set problem and, therefore, can be solved by a backtracking algorithm based on the D. Knuth’s Dancing Links X algorithm.
Besides solving the k-SAT problem, the code is also able to determine the solutions, if any, of an exact cover set problem.
Input and Output
For the k-CNF, the program reads an input from stdin containing integer numbers, where the first line corresponds to “k n m” (amount of literals, cardinal of U and number of clauses, respectively) and the following lines correspond to the clauses, where a number i represents the variable xi and -i its negation !xi (i.e., not xi).
The program output is send to stdout.
With the command line option -n the code prints out the number of different attributions that satisfy the input.
With the option -N, besides printing the number of attributions that satisfy the input, the code also prints all these attributions, line by line and in lexicographical order.
In case no option is passed through the command line, the code prints 1 if the k-CNF is satisfiable or 0, otherwise.
The command line option -C indicates that the input contains an exact cover set problem.
In this case, the input represents the problem of covering a set [n] = {1, 2, … , n} with elements from a collection of m subsets of [n].
The first line corresponds to “n m” (indicating the set [n] and the amount of subsets of [n], respectively) and the following m lines correspond to the subsets of [n], represented by integers belonging to [n] in ascending order.
As output, the code prints out the number of different solutions for the problem, followed by the respectively solutions, line by line and represented by numbers belonging to [n] in ascending order.
k-SAT as a Cover Set Problem
The k-SAT problem can be interpreted as a generalized cover set problem.
Adopting the convention 1 = true and 0 = false, one can represent a k-SAT by a matrix with the rows containing the possible values for which the variables {x1, x2, … , xn} can assume (0 or 1), and with the primary columns corresponding to the literals (columns that should be exactly covered, i.e., the subset of rows from a solution must contain exactly one 1 at each of those columns) and the secondary columns corresponding to the clauses {c1, c2, …, cm} which should be covered at least once by the set of rows of a given solution.
For example, consider the input:
3 4 5
-1 2 3
1 -2 4
1 -3 4
-1 -2 3
-1 2 -3
which corresponds to the following k-CNF:
(!x1 || x2 || x3) && (x1 || !x2 || x4) && (x1 || !x3 || x4) && (!x1 || !x2 || x3) && (!x1 || x2 || !x3)
Therefore, this boolean formula can be represented by the matrix:
x_1 x_2 x_3 x_4 c_1 c_2 c_3 c_4 c_5
x_1 = 0 | 1 0 0 0 1 0 0 1 1 |
x_1 = 1 | 1 0 0 0 0 1 1 0 0 |
x_2 = 0 | 0 1 0 0 0 1 0 1 0 |
x_2 = 1 | 0 1 0 0 1 0 0 0 1 |
x_3 = 0 | 0 0 1 0 0 0 1 0 1 |
x_3 = 1 | 0 0 1 0 1 0 0 1 0 |
x_4 = 0 | 0 0 0 1 0 0 0 0 0 |
x_4 = 1 | 0 0 0 1 0 1 1 0 0 |
Thus, as the primary columns (first four) correspond to an exact cover set problem, once selected the row xi = 0, the row xi = 1 cannot be in the solution, and vice-versa. However, the same criteria cannot be used for the columns representing the clauses, since a clause is satisfied when one or more literals are true.
In the example above, one attribution that satisfies the k-CNF is x1, x2 and x3 true and x4 false, represented by the rows x1 = 1, x2 = 1, x3 = 1 and x4 = 0 (or, in a compact form, 1110).
The X Algorithm
The X algorithm from D. Knuth is a backtracking search algorithm that can be applied to a class of combinatorial puzzle problems, that is to find all solutions of an exact cover problem. It’s based on a technique called dancing links: given a pointer x to an element from a double linked list, and let L[x] and R[x] be the pointers to the precedent and posterior elements, respectively, then the removal of x from the list is given by the operations:
L[R[x]] <- L[x]
R[L[x]] <- R[x]
However, since after removal the element pointed by x is still allocated in memory, its return to the list is given by the operations:
L[R[x]] <- x
R[L[x]] <- x
what allow thus return back to the previous stage (backtrack).
Given a matrix A of 0s and 1s, the X algorithm searches for all sets of rows containing exactly one 1 at each column.
The matrix A is then represented only by the 1s, with circular double linked lists for the rows and columns.
Each 1 in the matrix is represented by an structure containing four pointers for the preceding and posterior elements in the row and column, in addition to a pointer to the head of the column which it belongs to:
typedef struct node_struct {
struct node_struct *left, *right; /* predecessor and successor at row */
struct node_struct *up, *down; /* predecessor and successor at column */
struct col_struct *col; /* column containing this node */
} node;
The columns’ lists possess a head and the heads themselves also form a circular double linked list with a head called root.
Each element from a column list has an identifier given by a string, a counter with the updated amount of elements in the column and pointers to the precedent and posterior elements in the list and to the root:
typedef struct col_struct {
node head; /* list head (root) */
int len; /* actual number of items in this column list (not including head) */
char name[max_name]; /* symbolic identifier of the column for printing */
struct col_struct *prev, *next; /* neighbor columns */
} column;
The X algorithm scans the matrix A searching recursively for solutions as follows:
If 'A' is empty, print actual solution and return.
Otherwise, choose a column 'c' and do:
Cover column 'c'.
For 'r <- D[c], D[D[c]], ...', while 'r != c', do:
Include 'r' in the partial solution: 'partial <- r'.
For 'j <- R[r], R[R[r]], ...', while 'j != r', do:
Cover column from 'j' (i.e. 'C[j]').
Recursively call this algorithm for the reduced matrix 'A'.
Assign previous values: 'r <- partial' and 'c <- c[r]'.
For 'j <- L[r], L[L[r]], ...', while 'j != r', do:
Uncover column 'C[j]'.
Uncover column 'c'.
where D, U, L and R are pointers to the elements above and below in the column, and to the left and to the right in the row, respectively, and C[ j ] represents the column at which the element j belongs to. The operation of covering a column consists in removing the column head and all the rows it contains from top to bottom:
L[R[c]] <- L[c]
R[L[c]] <- R[c]
For 'i <- D[c], D[D[c]], ...', while 'i != c', do:
For 'j <- R[i], R[R[i]], ...', while 'j != i', do:
U[D[j]] <- U[j]
D[U[j]] <- D[j]
S[C[j]] <- S[C[j]] - 1
where S[C[ j ]] is the counter of the amount of elements at column j. The operation of uncovering a column is done in a reverse way as the covering procedure, i.e., from bottom to top:
For 'i <- U[c], U[U[c]], ...', while 'i != c', do:
For 'j <- L[i], L[L[i]], ....', while 'j != i', do:
S[C[j]] <- S[C[j]] + 1
U[D[j]] <- j
D[U[j]] <- j
L[R[c]] <- c
R[L[c]] <- c
Adaptation to the k-SAT Problem
As discussed above, the k-SAT problem can be mapped to a generalized cover problem, where the primary columns correspond to literals and the secondary ones to clauses. That is, the primary columns representing the literals have to be exactly covered, while the columns corresponding to the clauses should be covered at least once, since a clause is satisfied when one or more literals are true.
In order to adequate the X algorithm to the k-SAT problem it’s enough to modify the parts Cover column from 'j' and Uncover column from 'j'.
More specifically, these calls of the algorithms to cover and to uncover should be changed accordingly.
In the X algorithm described above, besides removing the column’s head, it removes also all its rows. This is fine for the primary columns, because once selected the row xi = 0, then the row xi = 1 cannot be in the solution, and vice-versa. However, when covering a secondary column (clause), its rows should not be removed as those rows could correspond to possible solutions that would discarded in case of removal. Therefore, for the secondary columns one should only remove the column’s head.
Moreover, it’s necessary to verify if the head of the secondary column was already removed. Since each clause has k literals, it’s enough to check if the number of elements in the column is equal to k. Thus, the variation of the cover algorithm for the secondary columns turns out to be:
If 'S[c] = k', do:
L[R[c]] <- L[c]
R[L[c]] <- R[c]
S[c] <- S[c] - 1
With a similar reasoning, a secondary column is uncovered only when the amount of elements is equal to k-1 and, therefore, the uncover algorithm for secondary columns becomes:
If 'S[c] = k - 1', do:
L[R[c]] <- c
R[L[c]] <- c
S[c] <- S[c] + 1
The structure representing the k-SAT problem has to be created in such way that the columns’ root is immediately before the primary columns and immediately after the secondary, and in the modified X algorithm one chooses to cover always a primary column c next to the root. Therefore, the k-SAT problem can be seen as a scan over a search tree with depth k:
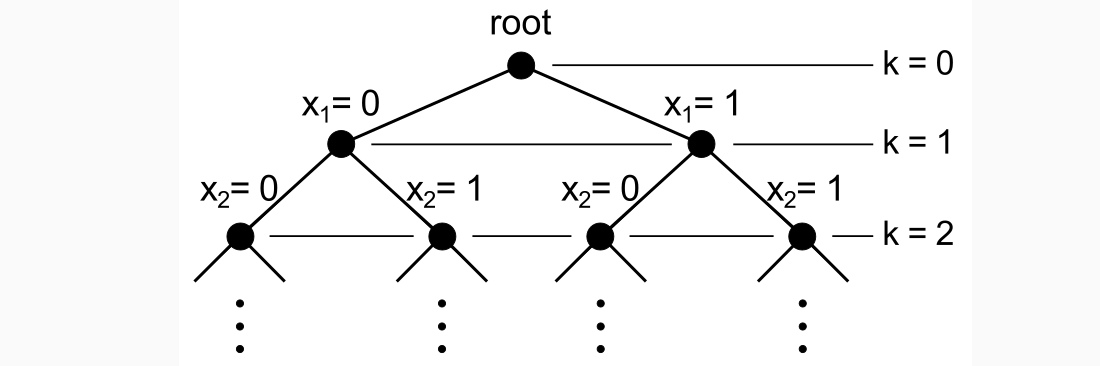
k-SAT representation as a search tree
Results and Critical Point Analysis
The probability that a k-CNF being satisfiable depends on the amount of clauses (m) and of literals (n). If the amount of clauses to be satisfied is large and the mount of literals is small, then smaller is the chances of the k-CNF being satisfiable. On the other hand, if the number of literals is large and the amount of clauses is small, then higher are the chances of the k-CNF to be satisfiable. It is believed that for all k there exists a constant ck with the following property:
Let q a constant and suppose that n tend to infinity. If m >= (ck+q)n, then the k-CNF is almost-certainly not satisfiable, while if m <= (ck-q)n, then it is almost-certainly satisfiable.
To estimate the constant ck for different values of k, the routine random_ksat.py from H. Yuen and J. Bebel has been used to generate pseudo-random instances of k-CNF, with a small modification to fulfill the input format described above.
For a fixed value of k, the quantities n >= k and m >= 1 were varied and, for each triple (k, n, m) a total of 50 pseudo-random instances of k-CNF were generated, from where the mean values of the amount of solutions and the execution time were calculated.
The obtained estimates for the constant ck are shown below:
| k | 2 | 3 | 4 | 5 | 8 | 10 |
|---|---|---|---|---|---|---|
| ck | 2.44 | 5.18 | 10.76 | 21.87 | 177.00 | 709.79 |
The graphs below show the mean values of the amount of solutions (log scale in both axis) and the execution time the plots (log sale in time), as a function of the number of clauses m and for different number of literals n. One observes that for m ~ ckn, the execution time is fairly higher.
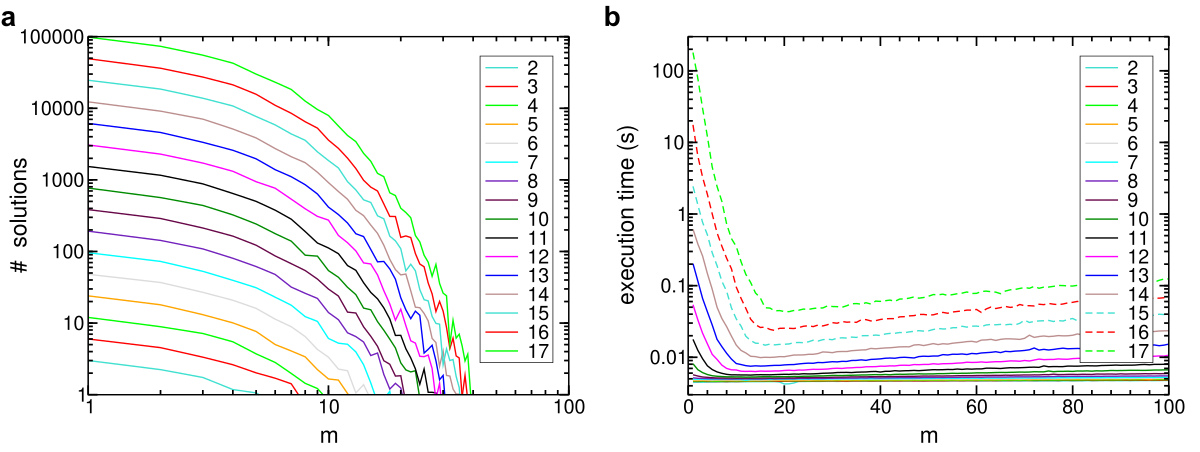
2-SAT: Mean values of solutions amount (a) and execution time in seconds (b) as a function of m, taken for different n.
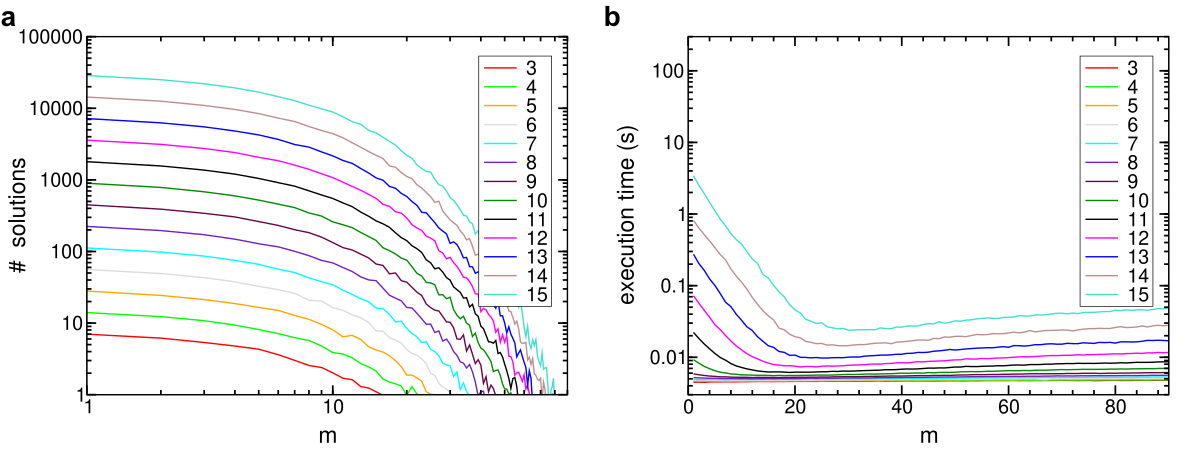
3-SAT: Mean values of solutions amount (a) and execution time in seconds (b) as a function of m, taken for different n.
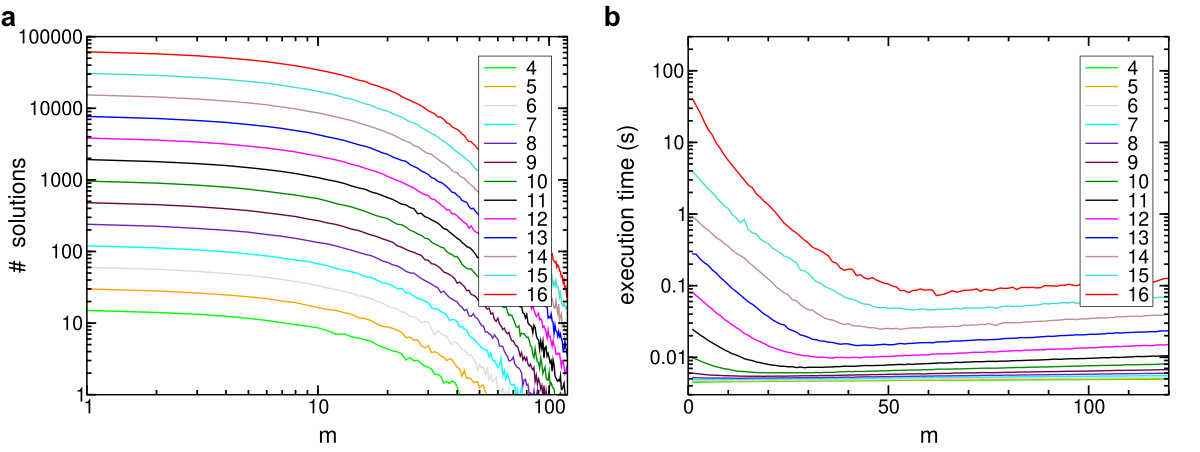
4-SAT: Mean values of solutions amount (a) and execution time in seconds (b) as a function of m, taken for different n.
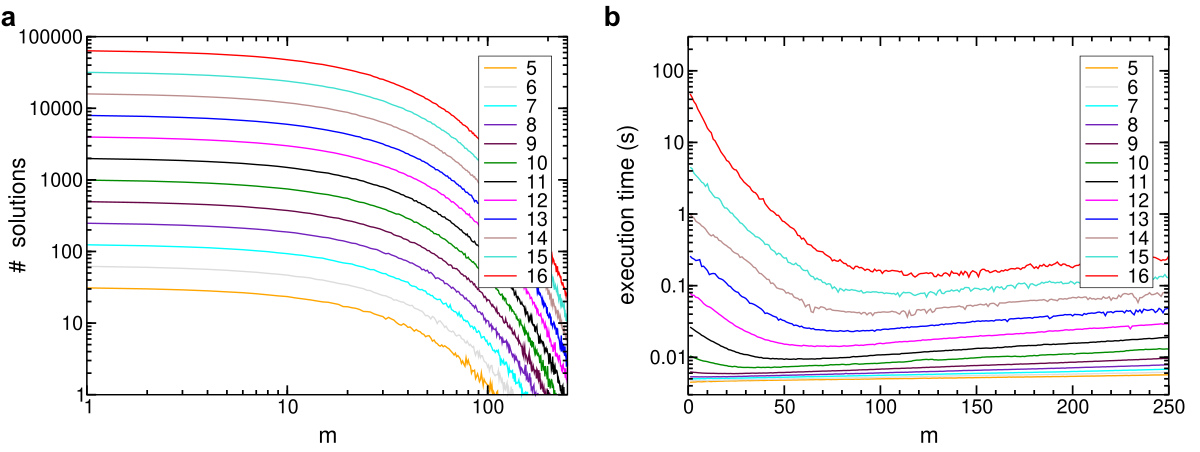
5-SAT: Mean values of solutions amount (a) and execution time in seconds (b) as a function of m, taken for different n.
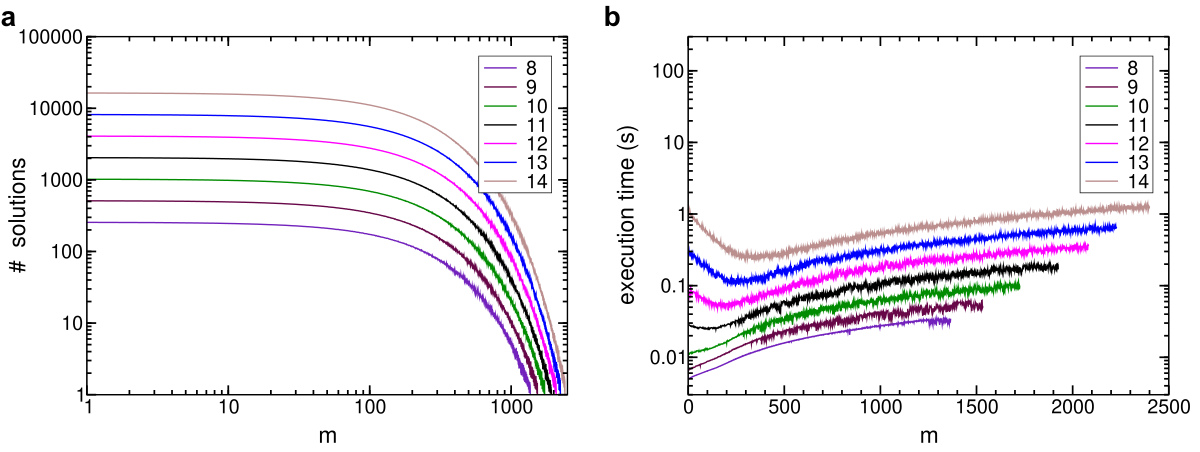
8-SAT: Mean values of solutions amount (a) and execution time in seconds (b) as a function of m, taken for different n.
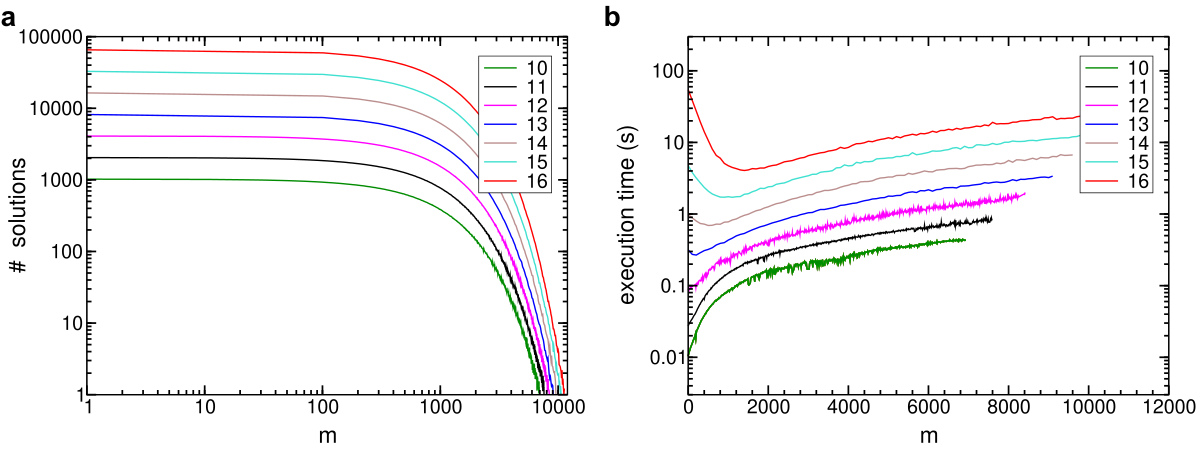
10-SAT: Mean values of solutions amount (a) and execution time in seconds (b) as a function of m, taken for different n.
Acknowledgments
PBM thanks Prof. Yoshiharu Kohayakawa for introducing the problem and pointing to Knuth algorithms.